Scaling View Synthesis Transformers
* Equal contribution
TL;DR: view synthesis transformers which achieve SoTA PSNR with 3x less FLOPs.
Abstract
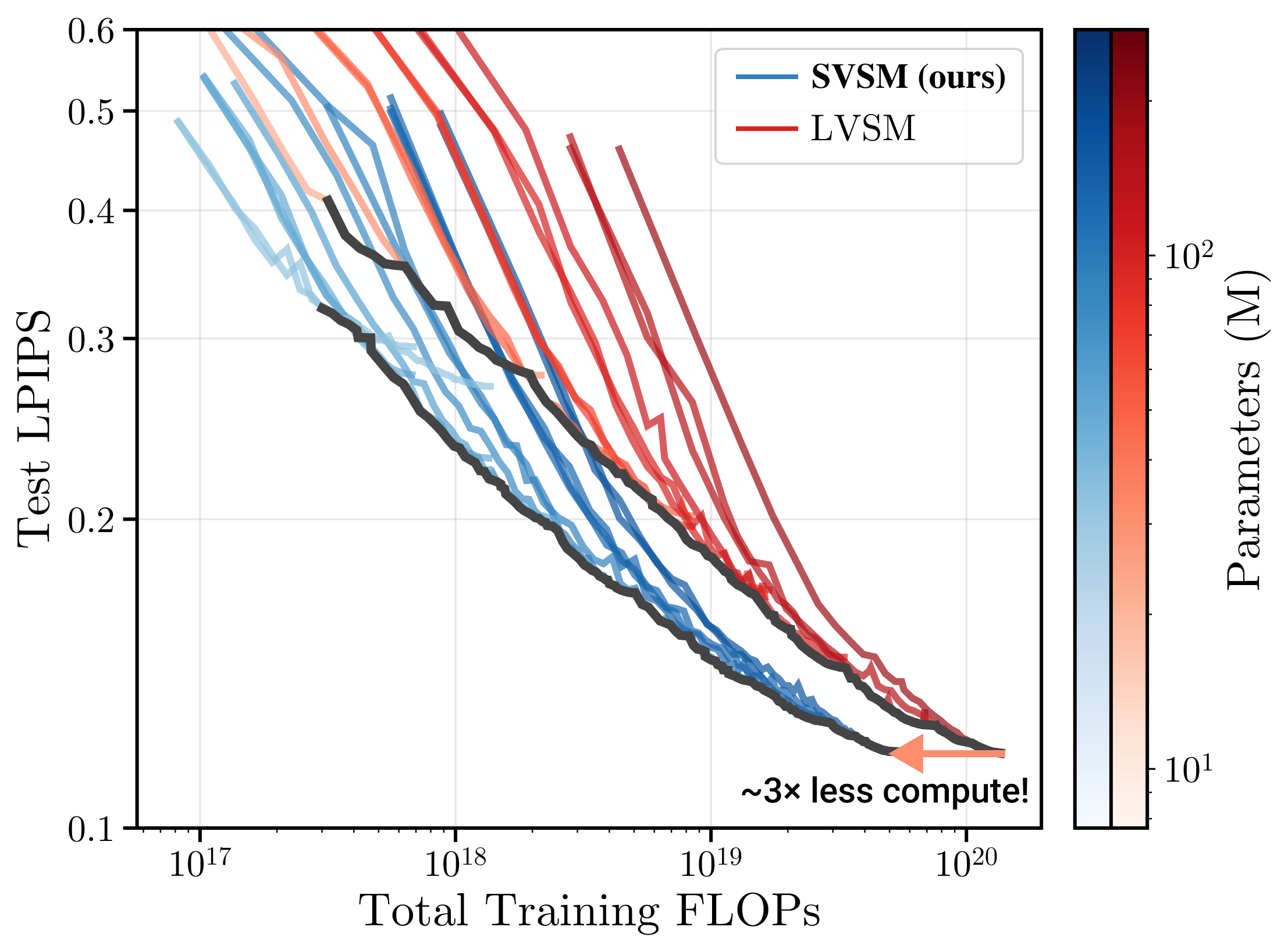
Geometry-free view synthesis transformers have recently achieved state-of-the-art performance in Novel View Synthesis (NVS), outperforming traditional approaches that rely on explicit geometry modeling. Yet the factors governing their scaling with compute remain unclear. We present a systematic study of scaling laws for view synthesis transformers and derive design principles for training compute-optimal NVS models. Contrary to prior findings, we show that encoder–decoder architectures can be compute-optimal; we trace earlier negative results to suboptimal architectural choices and comparisons across unequal training compute budgets. Across several compute levels, we demonstrate that our encoder–decoder architecture, which we call the Scalable View Synthesis Model (SVSM), scales as effectively as decoder-only models, achieves a superior performance–compute Pareto frontier, and surpasses the previous state-of-the-art on real-world NVS benchmarks with substantially reduced training compute.
Method Overview
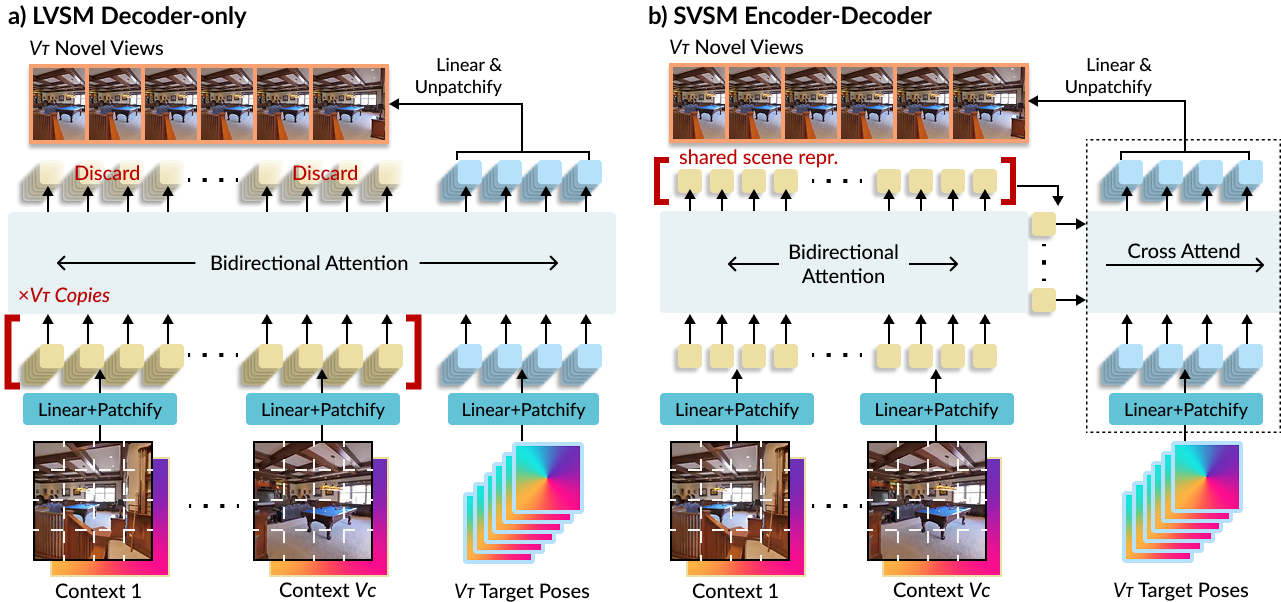
Encode once, decode many times.
Decoder-only LVSM recomputes context information for every target view rendered. SVSM instead uses an encoder-decoder design: a bidirectional encoder processes the context images once into latent tokens , then a cross-attention decoder renders each target view from this fixed representation. This reduces rendering complexity from to —a significant saving when rendering many views. The tradeoff: unlike LVSM, the encoder can't discard target-irrelevant information. But SVSM's compute efficiency lets us scale up model size and training steps such that, normalized by compute budget, SVSM significantly outperforms LVSM.
Why is this better? Effective Batch Size.
Training cost scales with both the number of scenes (batch size ) and target views per scene (). We find empirically that what matters is their product—the effective batch size . Configurations with the same achieve nearly identical performance (within ±0.2 PSNR).
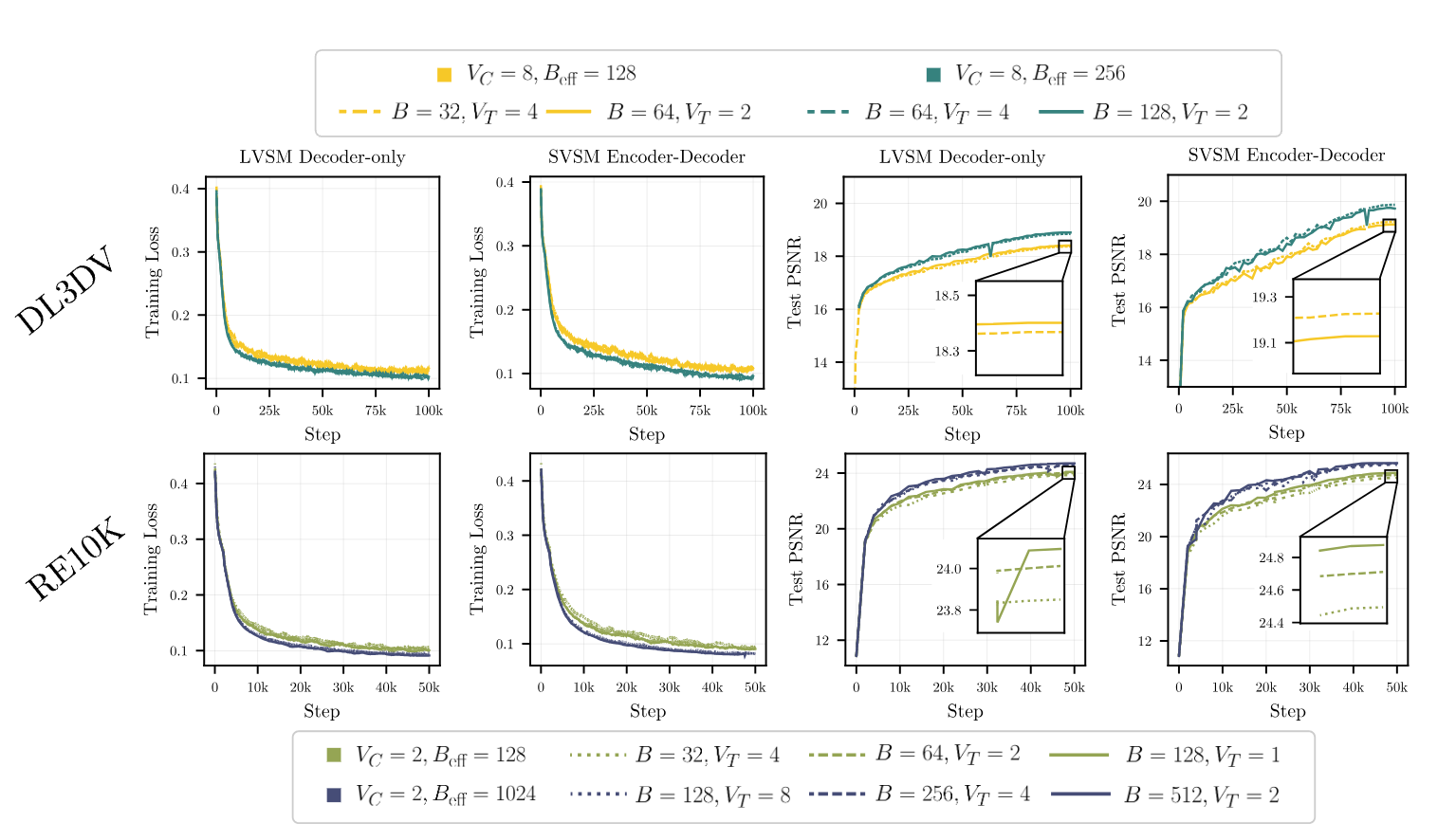
For decoder-only LVSM, compute scales as:
So there's no advantage to tuning —all configurations at fixed cost the same. In contrast, SVSM scales as:
By reducing and increasing , we achieve the same effective batch size—and performance—with lower compute. This justifies our encoder-decoder design that efficiently decodes multiple targets.
Results
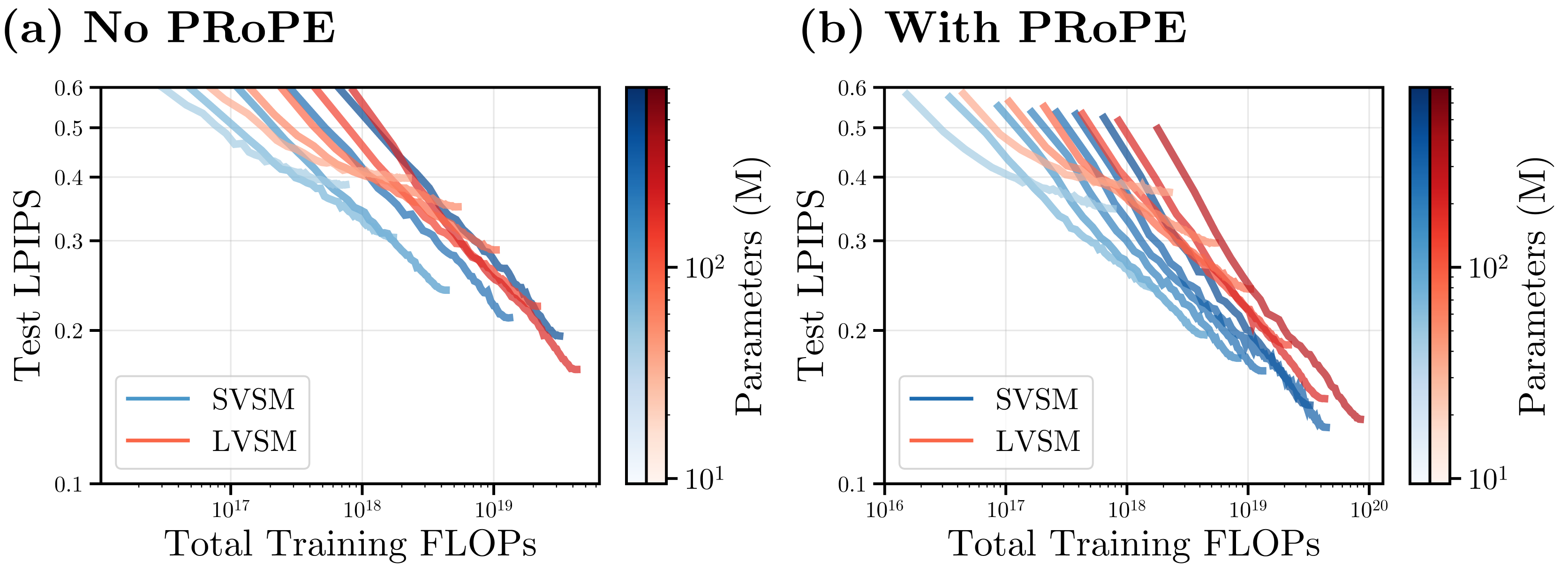
Scaling Laws: compute-efficent Pareto frontier.
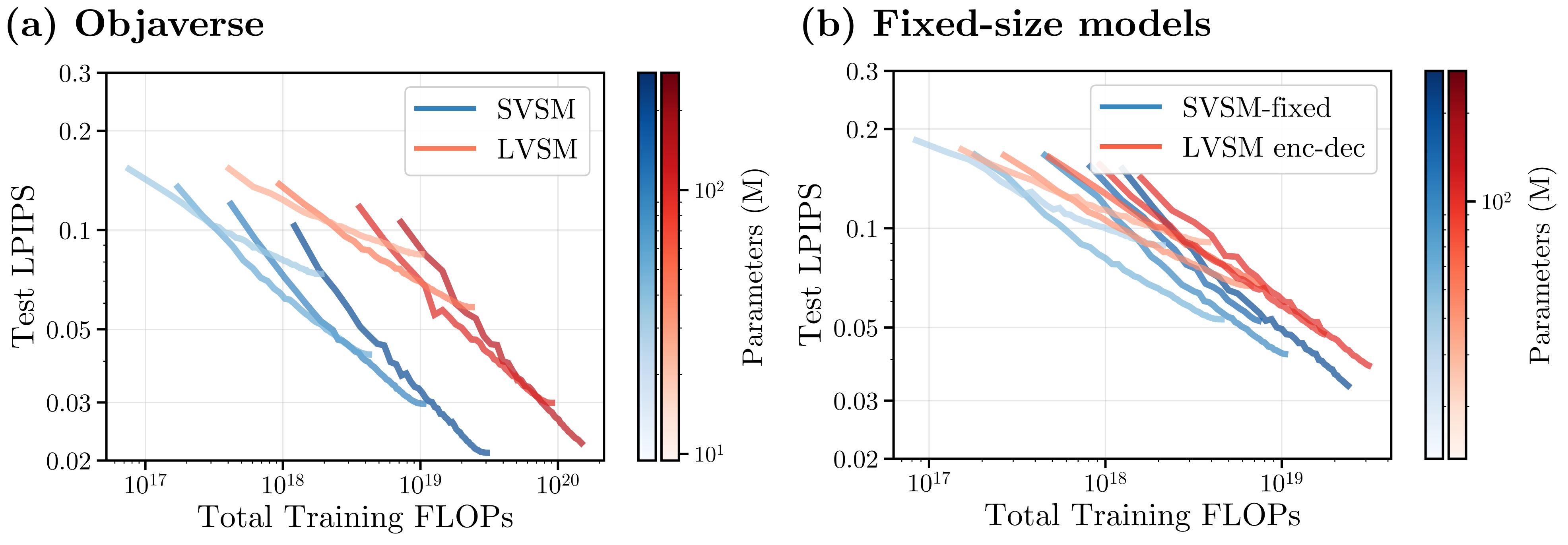
We evaluate our architecture rigorously by training both models on various compute budgets. We also test in several datasets and view context count settings: RE10K (2 context views), DL3DV (4 context views), and Objaverse (8 context views). In all cases, SVSM (in blue) consistently requires much less training compute to achieve the same performance as LVSM.
Qualitative Results: RE10K, DL3DV, Objaverse.



Citation
If you find this work useful, please cite:
@inproceedings{kim2026svsm,
title={Scaling View Synthesis Transformers},
author={Evan Kim and Hyunwoo Ryu and Thomas W. Mitchel and Vincent Sitzmann},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}